Cybersecurity & Standards, Government Surveillance
Matching Without Sharing: Benefits and Challenges of a PSI Technique
In early June, CDT’s Harley Geiger testified before the Senate Select Committee on Intelligence, chaired by Senator Feinstein, in a rare open hearing on the USA FREEDOM Act (H.R. 3361). The USA FREEDOM Act, a bill designed to reign in NSA surveillance, flew through The House and passed by a large margin in a bipartisan fashion. Unfortunately, just before the floor vote, the language was amended such that the provision to end bulk collection of Americans’ metadata was substantially weakened in several sections.
Discussion at the hearing focused on the difficult balancing act between national security and personal privacy: how can America provide for both of these national priorities? Chairwoman Feinstein, Vice Chairman Chambliss, and other committee members argued the bill’s current language, and the necessary creative interpretation it entails, is fundamental to continued intelligence effectiveness. CDT’s Geiger reiterated the concern that caused many of the bills’ original advocates to pull support after the amendment: this sort of creative statutory interpretation is what allowed for bulk collection in the first place, and H.R. 3361, despite the authors’ intent, makes no explicit guarantees that bulk collection will stop. This juxtaposition seems to be a catch-22; how do we allow national security the flexibility it needs to be effective while respecting the personal privacy of innocent parties?
The difficult balance between data aggregation and personal privacy isn’t exclusively an intelligence issue, we see it constantly in consumer privacy too. Last week the ephemeral messaging app, Snapchat, reached a settlement with the state of Maryland over a case involving privacy issues with their software. One of the primary complaints, mirrored in the FTC charges filed earlier this year, was Snapchat’s failure to properly secure data used by the “Find a Friend” feature that led to 4.6 million username/phone number pairs being leaked.
The problem facing the intelligence community and private sector are similar: how do we allow services, be it terrorist prevention or encrypted personal messaging, access to the information they need to be useful while preventing overcollection and possible exploitation or leakage of sensitive, private information? From a technical perspective, this is a matching problem – how do we allow for matching between sets of private or sensitive information without revealing the underlying information itself?
To think about this problem in more concrete terms, let’s look to a hypothetical situation posed by Chairwoman Feinstein on how to identify a known or suspected terrorist thought to be entering the country on a plane. Chairwoman Feinstein argued that law enforcement effectiveness relied on the ability to search passenger lists, which would necessarily result in the bulk collection of those lists, where most of the individuals on those lists are innocent.
Are there any techniques that would allow for quick, successful matching between passenger lists and a list of suspected terrorists without aggregating personal data from those passenger lists? That is, without the government having all passenger lists or the airlines having a highly sensitive list of suspected terrorists? A number of cryptographic techniques have been explored over the past decade to deal with exactly these sorts of difficult private matching problems, and a few exceptional techniques have begun to stand out. In particular, a technique known as Private Set Intersection (PSI) is among the most promising, with major advances in its practicality occurring over the past few years.
PSI, at an algorithmic level, is a method for two parties that do not trust each other to share mutually desired information, and only that information, without having to involve a trusted third party – like an escrow agent. In simpler terms, PSI is a method for matching between private sets of information without either party sharing information that the other party doesn’t have.
One technique, called Privacy-preserving Policy-based Information Transfer* (PPIT), is a PSI algorithm ideal for the challenge above. PPIT is particularly useful to us as it ends up scaling well, that is, it allows us to match small lists (sets) as well as large ones. Dense technical explanation aside, what does this actually mean for governments and companies? Let’s use the “terrorist on a plane” example to examine the practicality behind the jargon and demonstrate the usefulness of this technique.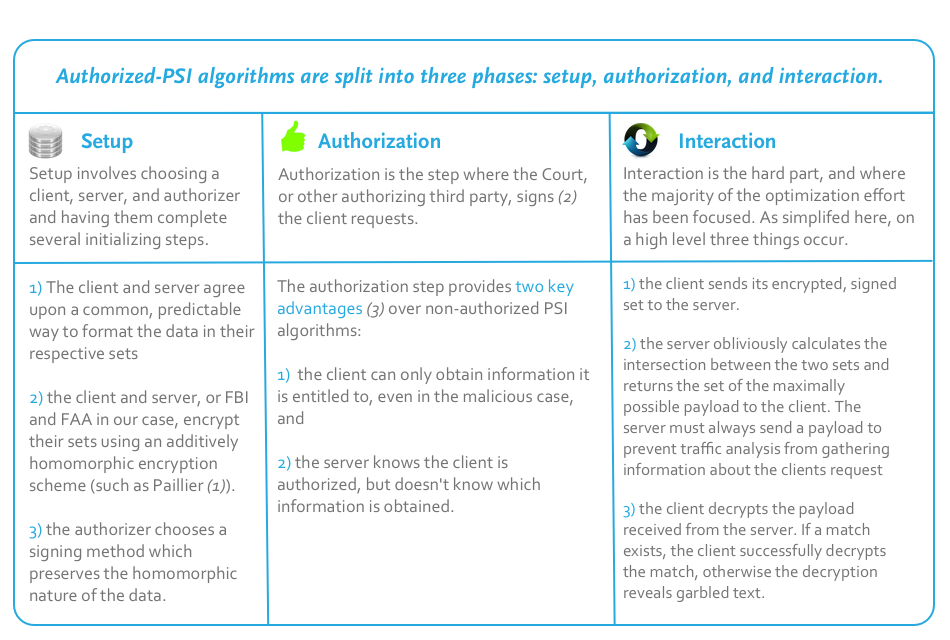
PPIT is a two-party PSI technique with optional authentication – in other words, we have two parties who, for the most part, don’t want to share raw data with each other. We also have an optional third party that authenticates the client requests so the server knows the requests are valid. In our case these two parties could be the FBI and the FAA. The FBI doesn’t want to share secret information pertaining to an investigation with the FAA. The FAA, to avoid over collection issues, doesn’t want to hand over all flight manifests to the FBI. In PPIT we assign the querier (the FBI) as the “client” and the data-holder (the FAA) as the “server”. Our third party (maybe a judicial authority) authenticates the requests made by the client so the server knows they are valid.
We are now faced with our primary technical challenge: how do we enable the server to securely and obliviously calculate the intersection between these two sets – i.e., where does the data match? The technique used by PPIT relies on a more general cryptography mechanism known as homomorphic encryption. Homomorphic encryption is a way to perform functions, such as calculating matches (intersections), on encrypted data, i.e., data you know nothing about. Until very recently the speed of these operations was exponential in the size of the lists – meaning it didn’t scale well to large lists that needed to be matched – and prohibitively expensive. Recent advances in the field have made very specific cases, such as PPIT, achievable in near-linear runtime – meaning it scales well to large lists too – and therefore practical on modern, typical computers.
Challenges
So, why hasn’t the government or the app developers we mention above adopted these types of techniques? In a nutshell, there have been some serious challenges to using these in production environments, some of which are becoming less of a challenge every day.
Speed: One of the biggest challenges for homomorphic encryption, PSI included, has been getting the algorithms to run at a reasonable speed. Recent advances have shown that PSI is definitely feasible for government purposes, and probably feasible for mobile users (mobile devices simply being very limited computers). Governmental situations often look like the query situation described above. These sorts of PPIT requests can be completed in well under a second for small server sets (under ten-thousand). For massive sets (a billion or more) alternative techniques, such as the server-aided PSI protocols developed by Microsoft, can be used for a slight increase in speed, which can make a big difference for large set matching problems. On the mobile front, promising advances, such as those published by Zhang et al. in 2012, show how secure friend matching can be achieved in a reasonably efficient manner.
Interoperability: From a perspective where you need to find intersections across organizations, such as almost all the queries that an intelligence agency would need to conduct, both organizations must agree on how the data should be formatted. This can be increasingly complex for specific queries these intelligence agencies may need to conduct. A quick, feasible, and testable method to ensure all participating sets are similarly formatted needs to be agreed upon. This is not a concern for application situations where the developer defines how the client and server communicate with each other.
Availability: Efficient PSI techniques are all relatively green technologies, and as such the most promising algorithms still seem to be confined to to the realm of white papers and private institutions, instead of being available in ready-to-use libraries that developers can simply drop into their applications. A few promising libraries exist, but they only implement one or two techniques and are confined to the authors prefered programming language with little testing or documentation. Before widespread implementation will happen, more general libraries in a variety of languages need to be created, especially for high performance languages such as C and C++.
Implementation: As always in cryptographic situations, mistakes that lead to exploits that can compromise user data are almost inevitable. Any developed library must be thoroughly tested and vetted before it can be trusted for critical applications.
Near the end of June’s hearing, Chairwoman Feinstein made a request to the public: “Enable us to do both the right thing for privacy and for this country”. The need for a method to match private information in an untrusted world has become obvious in both the private and public sector. With the difficulty that comes with balancing useful data aggregation and personal privacy in the public spotlight, it is important to keep the nature of technology in mind. Technology is not only a source of this difficulty, but also a provider of practical, innovative solutions. Private Set Intersection provides a practical tool to assist in achieving this difficult balance.
Further Reading:
(1) Paillier Cryptosystem, Wikipedia
(2) Cryptographic Signatures, Microsoft
(3) De Cristofaro & Tsudik, 2009, Practical Private Set Intersection Protocols with Linear Computational and Bandwidth Complexity, http://eprint.iacr.org/2009/491.pdf
(4) Freedman et al., 2004, Efficient Private Matching and Set Intersection, http://www.cs.princeton.edu/~mfreed/docs/FNP04-pm.pdf
(5) Zhang et al, 2012, Message in a Sealed Bottle: Privacy Preserving Friending in Social Networks, http://arxiv.org/pdf/1207.7199.pdf
(6) Kamara et al., 2013, Scaling Private Set Intersection to Billion-Element Sets, http://research.microsoft.com/apps/pubs/default.aspx?id=194141
(7) Dong & Chen & Wen, 2013, When Private Set Intersection Meets Big Data: An Efficient and Scalable Protocol, http://eprint.iacr.org/2013/515.pdf


