AI Policy & Governance, Privacy & Data
How does the internet know your race?
This post co-authored by Ali Lange and Rena Coen.
“The right message, to the right user, at the right time,” is the gold standard for advertisers. Entire industries, including internet empires, are built on the foundation of advertising dollars, and targeted advertising allows companies to connect people with content in a very granular way. Many of the ads you see online are tailored based on the information you share, knowingly or unknowingly. Your personal data feeds into to a multi-billion dollar industry of profiling and targeted advertising that includes not only information you shared directly, but also characteristics that are gleaned by analyzing aggregate data and behavior.
Your race is among many characteristics that can be inferred and used to serve you personalized content. In a 2014 report, the FTC described a handful of the categories used by data brokers which included “potentially sensitive categories … such as ‘Urban Scramble’ and ‘Mobile Mixers’, both of which include a high concentration of Latinos and African Americans with low incomes.” This practice makes people uncomfortable despite its widespread and longtime use in advertising, both online and off. Recent research by CDT and a team at the University of California Berkeley show that this practice continues to raise concerns with the public. We asked 748 people how they felt about online personalization based on a variety of characteristics, and personalization based on race achieved the most consistently negative results.
Facebook is a huge player in online advertising, making billions in ad revenue, and hosting over a billion users. To help advertisers target content to users, it uses a category called “ethnic affinity.” Though the company clarifies that the use of this category is not race-based targeting, it has faced similar backlash from the public. This spring, Facebook faced a high-profile example of the discomfort described above after it announced a partnership with Universal Pictures to show different versions of the trailer for the movie “Straight Outta Compton” to groups of people with affinities for ethnic categories. In the wake of the announcement, journalists, civil rights advocates, and academics raised concerns about the risks of segregating our online experience based on interests related to ethnicities.
Facebook’s option to target users based on “Ethnic Affinity” could make a big impact in how individuals perceive the world. The options within this category are: non-multicultural, African American, Asian American, and Hispanic. (Ars Technica pointed out that non-multicultural “presumably mean(s) white users.”) Again, Facebook is careful to state that their ethnic affinity categories are not the same as race. For example, if you “liked” BET (Black Entertainment Television) on Facebook, it’s possible that the algorithm would target you as part of the “African American” multicultural audience, no matter how you would describe yourself. While this is an improvement over the blatant racial targeting conducted by data brokers, this subtle distinction may not be intuitive to users.
Despite some controversy, it is safe to assume that personalization will continue to influence our digital experiences and that at least some content will be tailored to us based on our background. In addition to a larger political conversation, the “Straight Outta Compton” example raises questions about the ways that companies use our personal data. Most companies do not ask their users about their ethnicity or race — so how are they categorizing people? And how do people feel about this practice?
Facial Recognition
Your first instinct might be to assume companies use facial recognition software to categorize individuals into ethnic affinity groups. Spoiler alert: not likely.
Facial recognition technology compares attributes of a face, such as shape and distance between features, with huge databases of photos that have previously been identified in some way. For example, the comparison photos could be labeled with a trait such as race (either through self-identification or others categorizing the images). Then programmers instruct algorithms to identify the common traits among the “accurately” identified photos (this data set is called the “training data”), apply those metrics to an uncategorized population, and develop a guess as to the race of the unidentified photos. This technology has many applications and there is some evidence that inferring race from social media data is among them. Researchers at the University of Rochester recently analyzed profile photos scraped from Twitter to categorize and describe the demographics of followers of political candidates.
While it is technically possible to use facial recognition to infer race, we don’t see a great deal of evidence that this application of the technology is being used commercially. And there is no evidence that facial recognition is being used to determine Facebook’s Ethnic Affinity categories. (It is worth noting that facial features would be useful in describing someone’s phenotype, but that may or may not align with their race or ethnic affinity. Facebook is specifically focused on the latter.)
Proxies
There are characteristics that are so strongly correlated with race that to know them is to be able to infer someone’s race with reasonably high accuracy — zip code, language spoken, and surname can all be used as direct proxies for race. Institutions can compare discrete traits about individuals to an aggregate dataset (think census data), and infer their race pretty reliably (though not without some potential for error).
This technique can be used to protect consumers as well as to build out marketing profiles. The Consumer Financial Protection Bureau has published their methodology to infer race and ethnicity from a combination of geography and surname information. The purpose of identifying race in this context is to “conduct fair lending analysis to identify potential discriminatory practices in underwriting and pricing outcomes.” (In most cases, lenders are prohibited from considering race in an application and often don’t collect the data to avoid scrutiny.)
Machine Learning
The method above relies on inferring one characteristic directly from a second, related piece of information, or from a simple combination. However, race can be and sometimes is inferred by combining huge amounts of information and analyzing minute correlations found in the data.
As with facial recognition programs, other machine learning models begin with training data. A company might use training data that includes individuals’ self-described race to infer this information. Alternately, indicators of race may have been described in a rubric for relationships between attributes. (These rubrics present an opportunity for stereotypes to infiltrate the process, particularly when inferring race.) Finally, sophisticated algorithms can infer an individual’s race by comparing her online behavior (which may include expressions of her habits, preferences, and interests) to other people known or assumed to be in a particular racial or ethnic group.
This last technique may be entirely based on statistical correlation with no intentional logic for the connection. Algorithms can digest and analyze diverse combinations of data to draw correlations, and the connections they make may not have an obvious relationship to the underlying data. Consider a hypothetical example: a large enough data set may demonstrate a correlation between how quickly you scroll through a page and your gender. This kind of insight would not likely be intuitive for an average user, who might not realize that marketing would then be based on information they didn’t share (their gender) that was deduced using technology they may not understand.
How do people feel?
Concerns about data-driven discrimination are not limited to high-profile examples like Facebook’s “Straight Outta Compton” advertising campaign. There is evidence that people have a strong gut reaction against racially-determined personalization in other contexts as well. In the study that CDT conducted with a team from UC Berkeley, we asked individuals to rate how fair they felt it was to personalize advertisements, search results, or pricing based on race. As you can see in the graphic below, people felt differently about personalization within these contexts (there was less variation based on the source of the information–whether it was provided, accurately inferred, or inaccurately inferred). Our research suggests that people are largely uncomfortable with personalization based on race and proxies thereof, regardless of the source and accuracy. Even if a user has directly disclosed their race (“provided” it), personalization based on that trait remains unpopular.
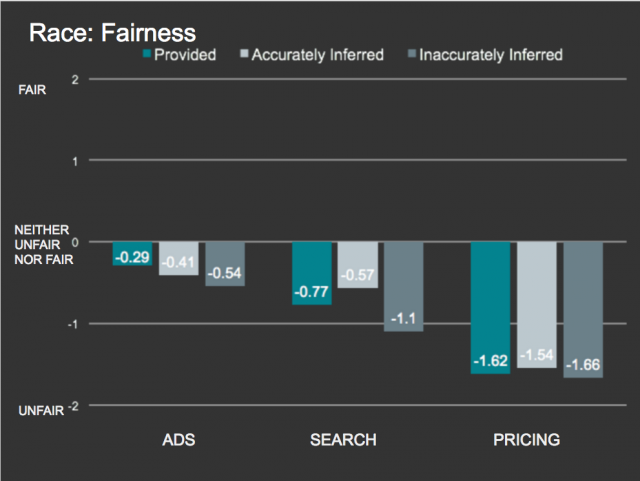
In our study, respondents described the use of inferred race for targeted advertising to be “somewhat unfair” (-0.41 or -0.54 depending on the accuracy). In the Facebook example discussed later in this article, personal data was used to tailor advertisements based on a person’s ethnic affinity. Facebook guessed this information, or, in the terms used in our study, “race was inferred.”
Where does this leave us?
One thing is clear: people are not excited when they find out that advertisements are targeted to them based on their race. A handful of our study participants had extreme reactions to the notion of race-based targeting — one respondent observed about tailored news based on race, “This sounds like something the KKK would do.” In the face of strong opinions like this, the subtle distinction between Ethnic Affinity and race is unlikely to stand up to the scrutiny of popular opinion.
The distinction may be particularly difficult to highlight when individuals don’t understand the process that is being used to categorize them, or the nuances of the categories themselves. As data sets grow larger and more complex algorithms consider a greater number of characteristics, the relationship between the information we share and the traits inferred from it becomes nebulous to the point of obscurity. As a result, inference based on these models can understandably surprise and upset people.
That said, the technology itself is not to blame for people’s reactions. There are applications that promote civil rights (see: the CFPB example used above) or convenience in inclusive ways. For example, a company that makes a product for a particular hair or skin type will want to target those customers. It is possible that in some cases people would respond more positively if they understood the technical workings behind inferring ethnic affinity as explained in this blog post, but either way it is clear that companies are going to have to overcome a negative gut reaction to the practice.


